はじめに
みなさん、こんにちは!業務ハックLabのようです。
この記事は「Microsoft Power Automate Advent Calendar 2025」の12月22日担当分の記事です。
前回はシステムの全体像とSharePointの準備まで完了しましたね!
(SharePointのリスト、ちゃんと作れましたか?)
今回からいよいよPower Automateで実際にフローを作っていきますよ!
はい、ここからが本番です。
変数の初期化とか、APIキーの設定とか、ちょっと細かい作業が続きますが、一つずつ丁寧に進めていけば大丈夫です!
(僕も最初は「変数多すぎ!」って思ったんですが、後で見返すと「ああ、だからこうなってるのか」って納得できますから)
今回の目標
第2回では、以下のことを実現します。
実装する内容:
- Power Automateフローの新規作成
- SharePointトリガーの設定
- 必要な変数の初期化(8個!)
- ファイル内容の取得
まだAzure AIは登場しません。
今回は「データを受け取る準備」の段階ですね。
では、行ってみましょう!
Phase 2: Power Automateフローの作成
2-1. 新しいフローの作成
まずはPower Automateにアクセスしましょう。
手順:
- Power Automate (https://make.powerautomate.com/) にアクセス
- 左メニューから「作成」をクリック
- 「自動化したクラウドフロー」を選択
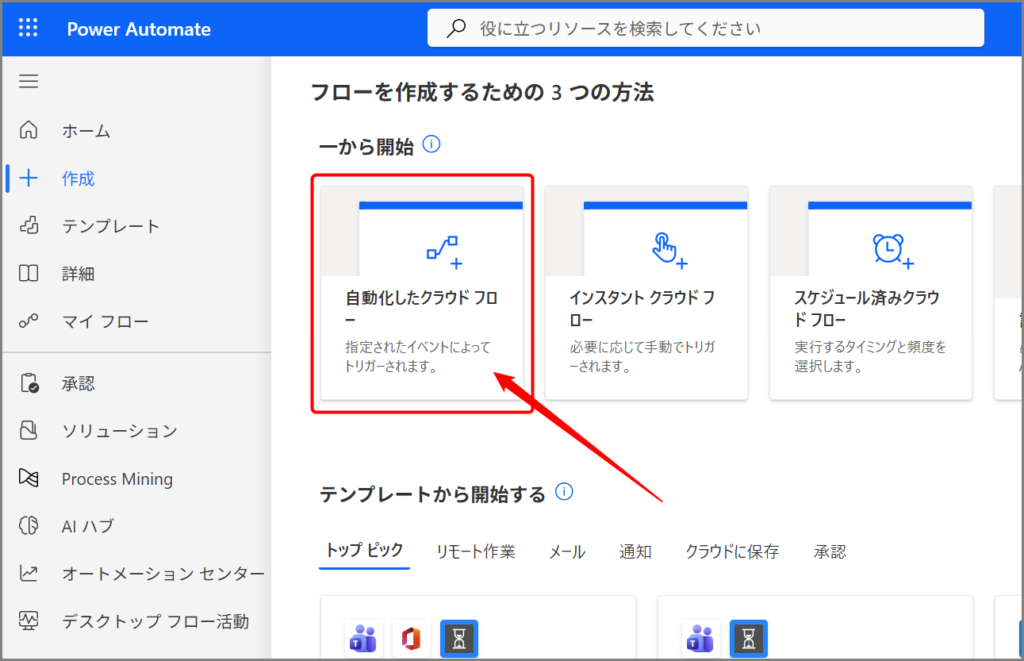
すると、フロー作成のダイアログが表示されます。
設定内容:
- フロー名: 契約書リスク自動分析
- トリガー: SharePoint – ファイルが作成されたとき(プロパティのみ)
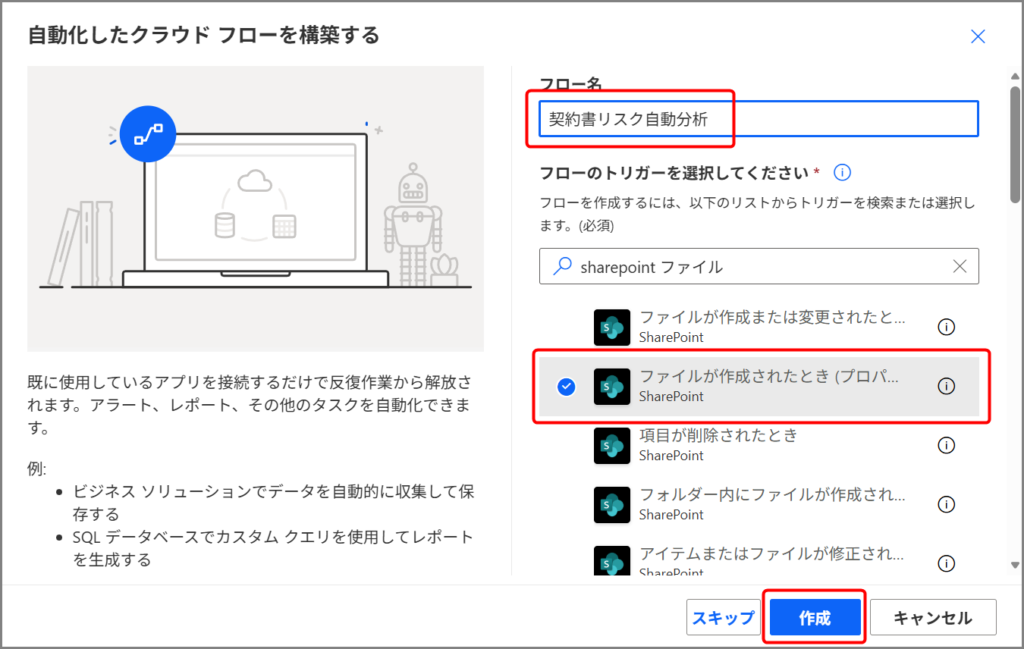
トリガーを選ぶ時は、検索ボックスに「sharepoint ファイル」って入力すると見つけやすいですよ。
はい、「作成」ボタンをクリックしましょう!
2-2. トリガーの設定
フローが作成されると、トリガーの設定画面が表示されます。
ここで、どのSharePointサイトのどのライブラリを監視するかを指定します。
設定内容:
| 項目 | 設定値 |
|---|---|
| サイトのアドレス | 契約書を保管するSharePointサイト(前回作成したサイトを選択) |
| ライブラリ名 | 契約書(前回作成したドキュメントライブラリ) |
| フォルダー | (特定のフォルダーに限定する場合のみ指定。今回は空欄でOK) |
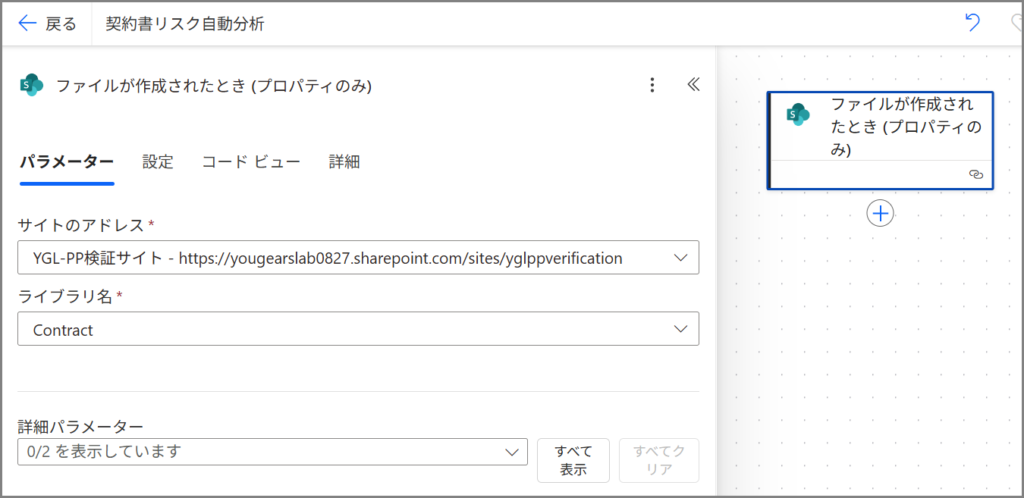
「サイトのアドレス」のドロップダウンをクリックすると、アクセスできるSharePointサイトの一覧が表示されます。
前回作成したサイトを選んでください。
(もし一覧に出てこない場合は、「カスタム値の入力」から直接URLを入れることもできますよ)
はい、トリガーの設定はこれで完了です!
Phase 3: 変数の初期化
さあ、ここからが少し長いんですが、めちゃくちゃ重要な部分です。
フローで使う変数を一気に8個作っていきます!
(「変数って何に使うの?」って思うかもしれませんが、APIのエンドポイントやキーを保存しておくための「箱」だと思ってください)
変数を初期化する – 基本操作
まず、変数の追加方法を確認しておきましょう。
手順:
- トリガーの下にある「+新しいステップ」をクリック
- 検索ボックスに「変数」と入力
- 「変数を初期化する」を選択
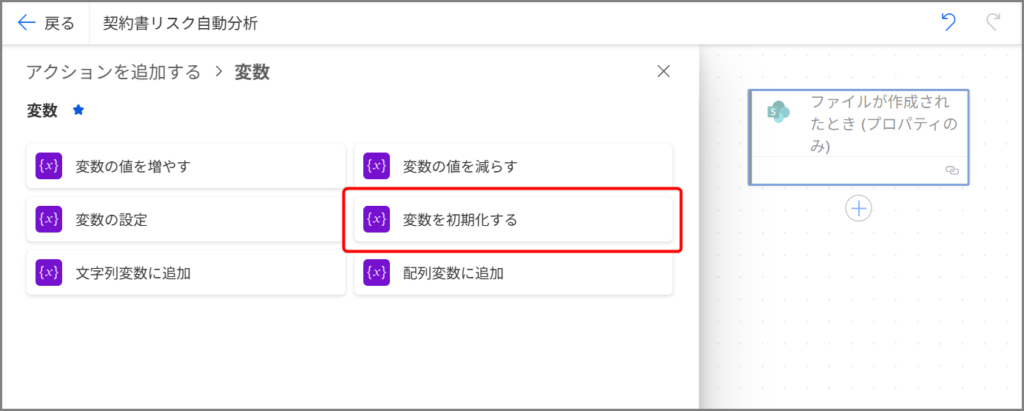
これを8回繰り返して、以下の変数を作っていきます。
(大変だけど、コピペミスに注意しながら進めてくださいね!)
3-1. Azure エンドポイントとキー(5個)
まずは、Azure関連の情報を格納する変数から作ります。
今回は簡易的に作る為、変数に「キー」を格納していますがこれだとセキュリティ的にちょっとリスキーです。
実際に運用する時は「キー」に関してはAzure Key Vault使いましょうね。
変数1: Document Intelligence エンドポイント
| 名前 | var_DocIntelEndpoint |
| 種類 | 文字列 |
| 値 | https://[あなたのリソース名].cognitiveservices.azure.com/ |
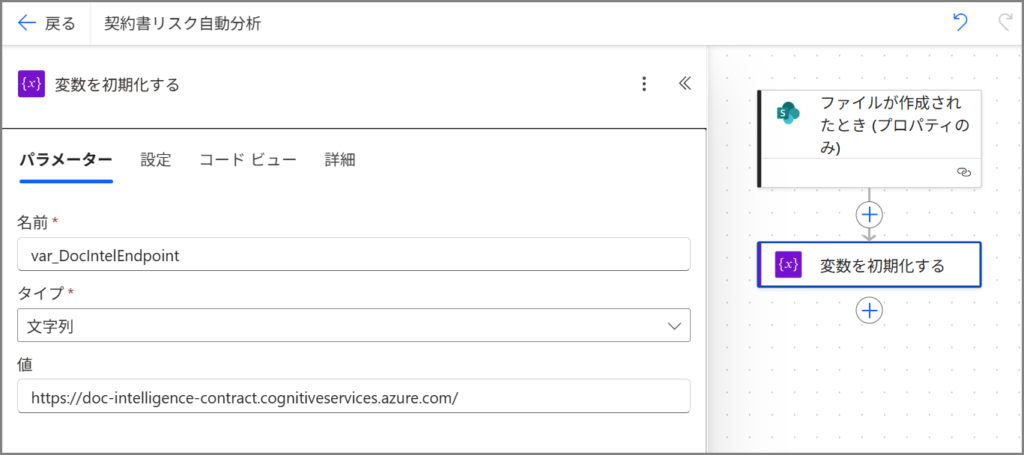
⚠️ 重要: 最後の「/」(スラッシュ)を忘れずに!
これがないとAPIが動きません。
変数2: Document Intelligence キー
| 名前 | var_DocIntelKey |
| 種類 | 文字列 |
| 値 | Azureポータルから取得したキー(キー1またはキー2) |
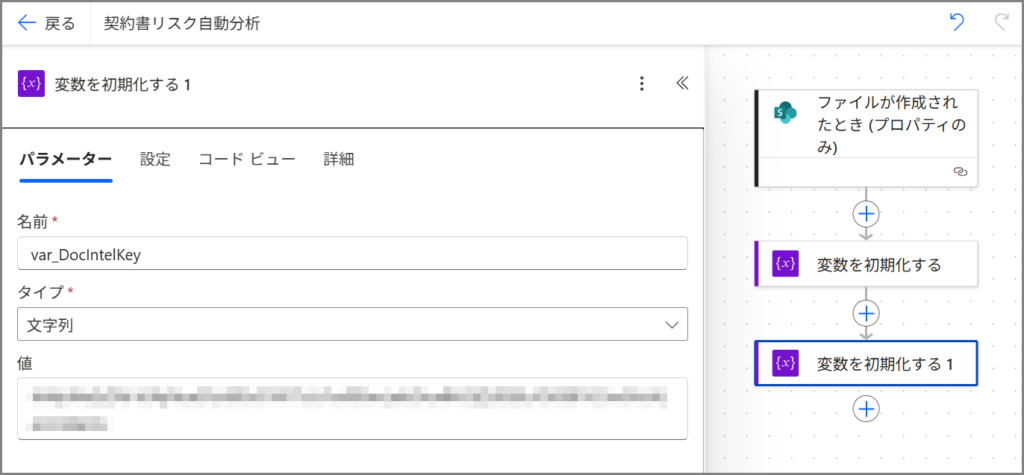
(これ、32文字くらいの英数字の文字列です。コピペする時に空白が入らないように注意!)
変数3: Azure OpenAI エンドポイント
| 名前 | var_OpenAIEndpoint |
| 種類 | 文字列 |
| 値 | https://[あなたのリソース名].openai.azure.com/ |
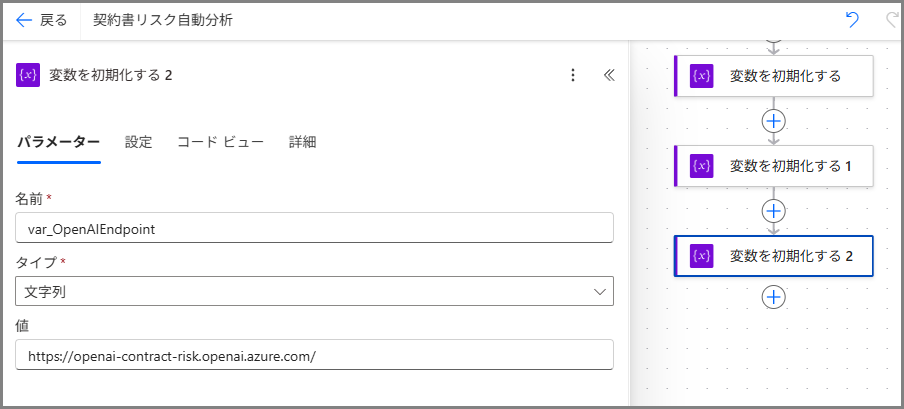
これも最後のスラッシュを忘れずに!
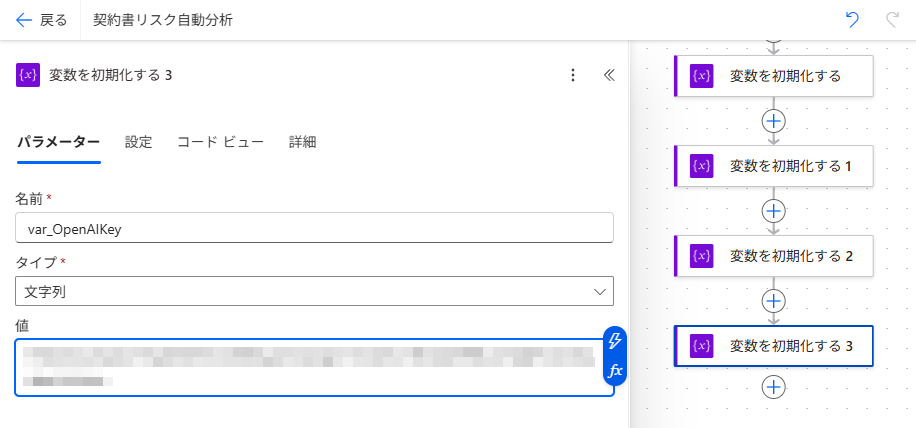
変数4: Azure OpenAI キー
| 名前 | var_OpenAIKey |
| 種類 | 文字列 |
| 値 | Azureポータルから取得したキー(キー1またはキー2) |
変数5: デプロイ名
| 名前 | var_DeploymentName |
| 種類 | 文字列 |
| 値 | gpt-4.1 |
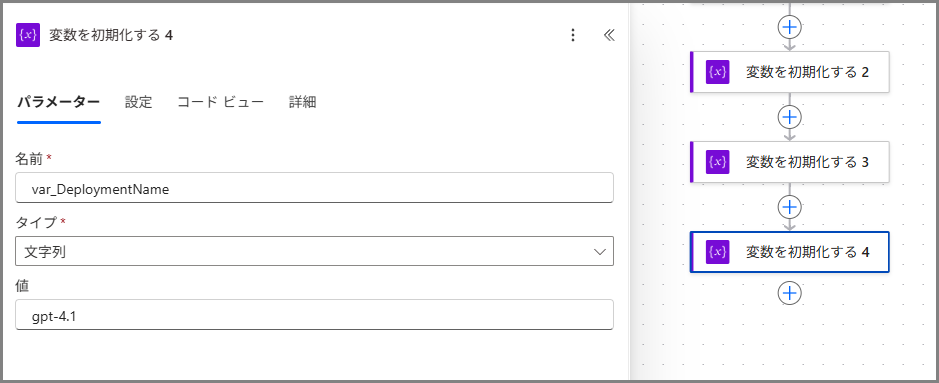
これはAzure OpenAI Studioで設定したデプロイメントの名前です。
(人によっては「gpt-4-32k」とか「my-gpt4」とかになってるかもしれません)
3-2. システムプロンプト(超重要!)
次は、AIに「どういう分析をしてほしいか」を指示するためのプロンプトを変数に格納します。
これ、めちゃくちゃ長いんですが、これがシステムの核心部分なので丁寧にコピーしてくださいね!
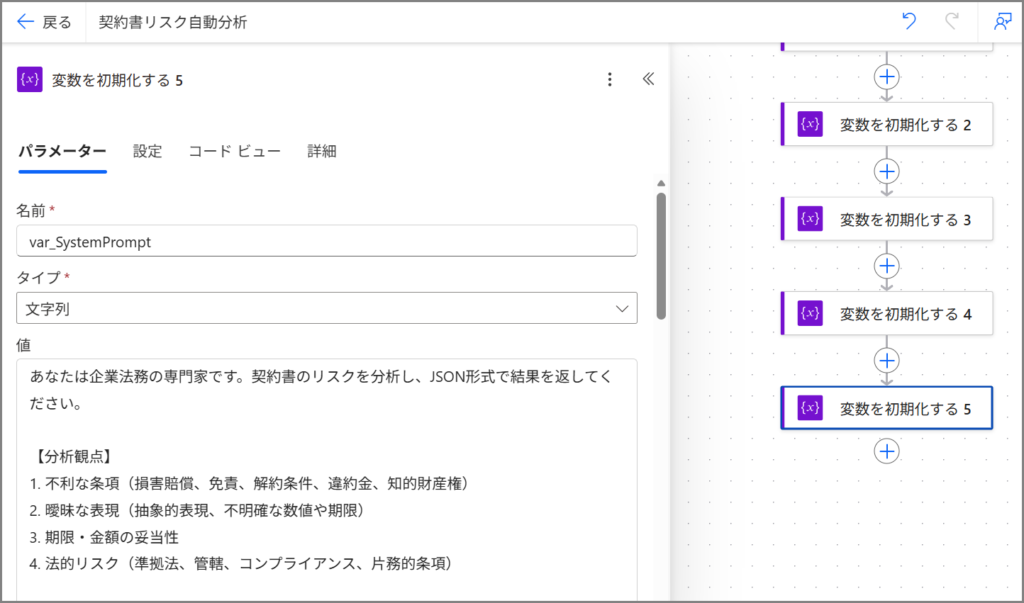
変数6: システムプロンプト
| 名前 | var_SystemPrompt |
| 種類 | 文字列 |
| 値 | 下記参照 |
システムプロンプトの内容:
あなたは企業法務の専門家です。契約書のリスクを分析し、JSON形式で結果を返してください。
【分析観点】
1. 不利な条項(損害賠償、免責、解約条件、違約金、知的財産権)
2. 曖昧な表現(抽象的表現、不明確な数値や期限)
3. 期限・金額の妥当性
4. 法的リスク(準拠法、管轄、コンプライアンス、片務的条項)
【必須出力形式】
必ず以下のJSON形式で出力してください:
{
"overall_risk_level": "高/中/低のいずれか",
"risk_score": 0から100の数値,
"summary": "100文字程度の総合評価",
"high_risk_items": [
{
"category": "リスクのカテゴリ名",
"description": "リスクの具体的な説明",
"clause_reference": "該当する条項の引用または番号",
"severity": "高",
"recommendation": "推奨される対応策"
}
],
"medium_risk_items": [
{
"category": "カテゴリ名",
"description": "説明",
"severity": "中"
}
],
"low_risk_items": [
{
"category": "カテゴリ名",
"description": "説明",
"severity": "低"
}
],
"positive_points": ["契約書の良好な点のリスト"]
}
【重要】
- JSON形式のみを出力し、説明文は含めない
- 実際の条項を引用して具体的に指摘
- リスク項目がない場合は空の配列 [] を返す
はい、このプロンプトがAIに「こういう形式で分析してね」って指示を出してるわけです。
(実際に運用してみて、「もうちょっとこういう観点も欲しいな」って思ったら、ここを修正すればOKです!)
3-3. その他の変数(2個)
あと2つ、変数を作ります!
変数7: Operation Location
| 名前 | var_OperationLocation |
| 種類 | 文字列 |
| 値 | (空白のまま) |
これは後でDocument Intelligenceが処理結果を返してくれるURLを格納するための変数です。
最初は空っぽでOK。
変数8: 高リスク項目テキスト
| 名前 | var_HighRiskText |
| 種類 | 文字列 |
| 値 | (空白のまま) |
これは高リスク項目を整形してSharePointに保存する時に使います。
これも最初は空っぽ。
変数の確認
はい、お疲れ様です!
これで8個の変数が揃いました。
念のため、変数名を確認してみましょう。
作成した変数一覧:
var_DocIntelEndpointvar_DocIntelKeyvar_OpenAIEndpointvar_OpenAIKeyvar_DeploymentNamevar_SystemPromptvar_OperationLocationvar_HighRiskText
全部揃ってますか?
揃ってたら次に進みましょう!
(もし変数名が違ってたら、後で「あれ?動かない!」ってなるので、今のうちに確認しておくと安心です)
Phase 4: ファイル内容の取得
さあ、いよいよファイルの中身を取得していきます!
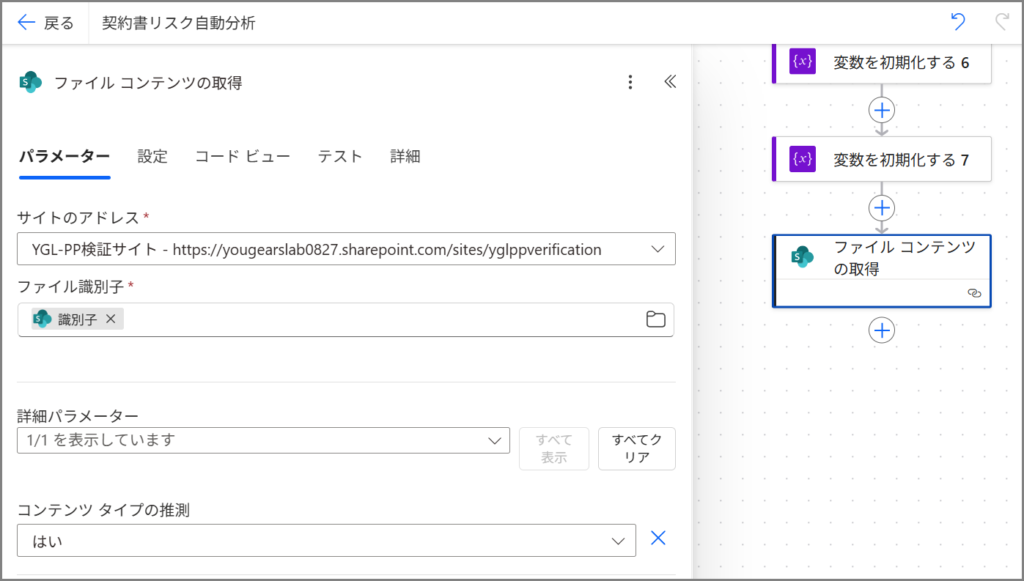
4-1. ファイル コンテンツの取得
変数の初期化が終わったら、次のステップを追加します。
手順:
- 「+新しいステップ」をクリック
- 検索ボックスに「sharepoint ファイル コンテンツ」と入力
- 「SharePoint – ファイル コンテンツの取得」を選択
設定内容:
| 項目 | 設定値 |
|---|---|
| サイトのアドレス | トリガーと同じSharePointサイトを選択 |
| ファイル識別子 | 動的コンテンツから「識別子」を選択 |
「ファイル識別子」のところ、ちょっと注意が必要です。
入力欄をクリックすると、右側に「動的なコンテンツ」というパネルが出てきます。
そこに「ファイルが作成されたとき」のトリガーから使える値が一覧表示されてるんですね。
その中から「識別子」を探してクリックしてください。
はい、これでファイルの中身が取得できるようになりました!
ここまでの確認
さあ、ここまでで基礎部分が完成しました!
フローを上から見ていくと、こんな感じになってるはずです。
現在のフロー構成:
- トリガー: ファイルが作成されたとき
- 変数を初期化する × 8回
- ファイル コンテンツの取得
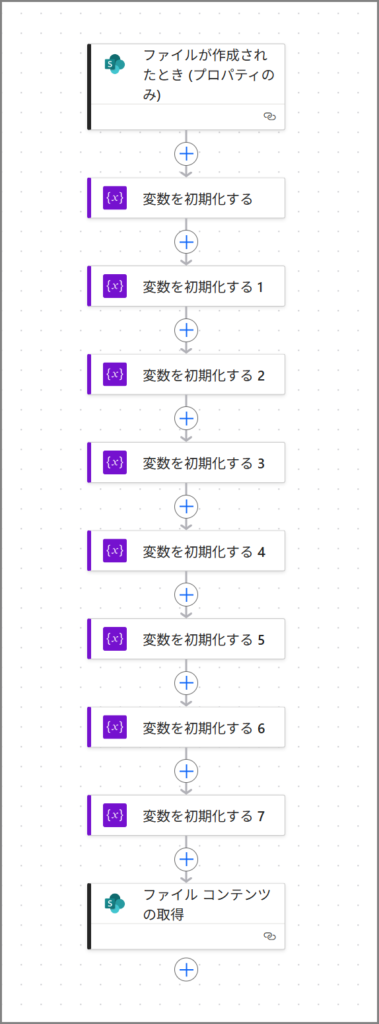
ここまで作れてたら、もう半分は完成したようなもんです!
(いや、実際にはまだまだあるんですけど、気持ち的にはね!)
保存してテストしてみましょう
一旦、フローを保存してテストしてみましょう。
手順:
- 画面右上の「保存」ボタンをクリック
- 「テスト」ボタンをクリック
- 「手動」を選択して「テスト」
- SharePointの「契約書」ライブラリに何かPDFファイルをアップロード
フローが実行されて、すべてのステップに緑のチェックマークが付けばOKです!
(もしエラーが出たら、変数の値やファイル識別子の設定を見直してみてください)
まとめ
はい、如何でしたでしょうか?
第2回では、Power Automateフローの基礎部分を作り上げました!
今回やったこと:
- Power Automateフローを新規作成
- SharePointトリガーを設定
- 8個の変数を初期化(Azure関連情報、システムプロンプト)
- ファイル内容の取得
- 動作確認のテスト実行
変数の初期化、ちょっと大変でしたよね。
でも、これがあるからこそ、後の処理がスムーズに動くんです!
(僕も最初は「こんなに変数作るの?」って思ったけど、運用してみると「ああ、これ分けといて良かった」ってなります)
次回(第3回)では、いよいよAzure Document IntelligenceとAzure OpenAIを使った本格的なAI分析部分を実装していきます!
ここが一番面白いところなので、楽しみにしててください!
(HTTPアクションとかJSON解析とか、ちょっと難しそうに見えるけど、一つずつ解説していきますよ!)
それでは皆さん、良い業務ハックライフを~
連載記事:
- 第1回:システム概要・準備編
- 📍 第2回:基礎実装編(今回)
- 第3回:AI分析実装編(次回予告)
- 第4回:完成・運用編
コメント