
みなさん、こんにちは!業務ハックLabのようです。
最近、ちょっと機会があってDataverseをちょこちょこ触るようになりました。で、今回どうしても気になって実際に検証してみたことがあるんですよ。
それが、「Dataverseの検索って、日本語だとなんか弱くない?」というモヤモヤです。
「検索が当たらない」のって、自分のせいじゃないんです
こんな経験ありませんか?
Dataverseにデータを入れて、モデル駆動型アプリで検索してみたら……ヒットしない。
「え、設定間違えたかな?」とドキドキしながら列の設定を確認しても、問題なさそう。もう一度検索してみる。やっぱりヒットしない。(おかしい、絶対このデータ入ってるはずなのに……)
これ、僕も何度か経験しました。そして今回、2つの環境を用意して実際に並べて検証してみた結果、ある「残酷な真実」が見えてきました。
結論を先に言います。あなたの設定は間違っていません。これは仕様の壁です。
今回は、その「壁」の正体を検証データをもとに解説します!
まず検証環境を整える
「感覚論にしたくない」と思って、今回はちゃんと条件を揃えた環境を2つ用意しました。
- 環境A(日本語環境):リージョン 米国(早期)/UI言語 日本語/検証データ 5,000件
- 環境B(英語環境):リージョン 米国(早期)/UI言語 英語/検証データ 5,000件
リージョンはあえて同じにしました。「地域の問題なのか、言語の問題なのか」を切り分けるためです。(ここが検証のキモだと思っていました)
※2026/4/11追記
環境Cとしてリージョン 日本/UI言語 日本語/検証データ 5,000件 という環境を作った結果、そもそもDataverse 検索自体が表示されませんでした。(検証漏れてた・・・)
ちなみにDataverse 検索の有効化については下記公式ページに設定方法が書いています。
既存の環境で Dataverse の検索を構成する – Power Platform | Microsoft Learn
【検証①】英語環境での「頭の良さ」
まず英語環境でやってみたんですが、流石!という感想。
検索ボックスに「erorr」と入力したんです。わざとスペルミスです。「e-r-o-r-r」。本来は「error」ですよね。
ところが!
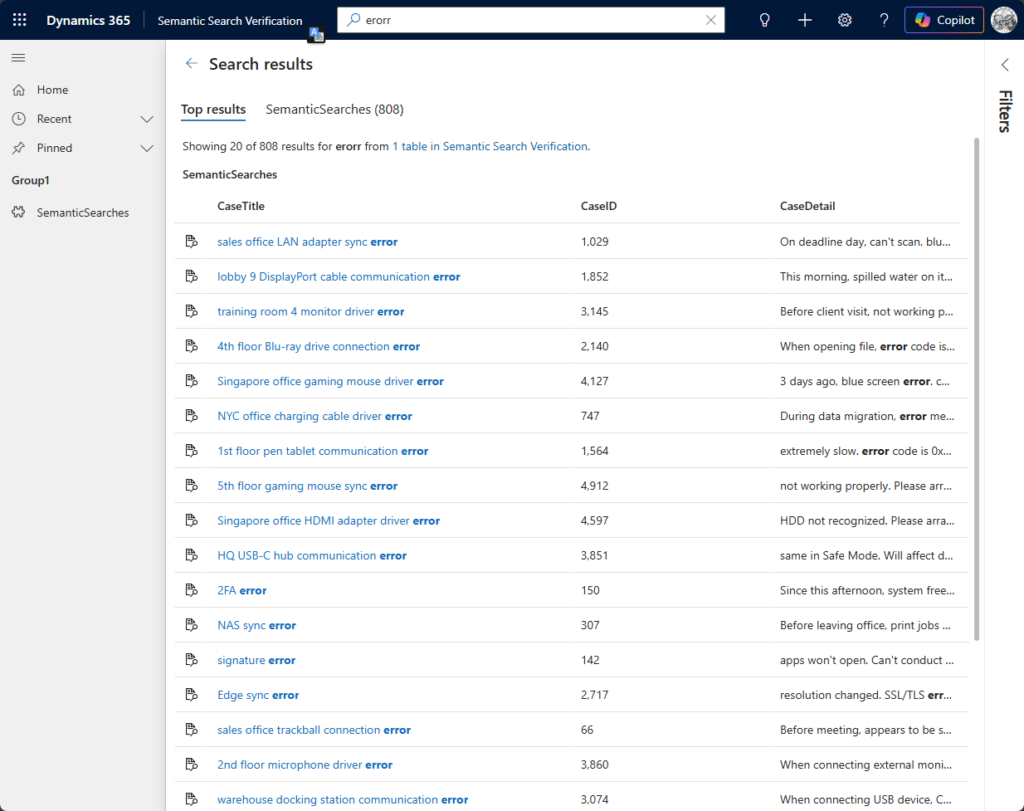
画面にShowing results for errorというメッセージが出て、ちゃんと「error」関連のデータがヒットしてきました。
タイポを自動補正して、さらに「こっちで検索しましたよ」って教えてくれる。
Dataverseの検索エンジン、英語に対しては本当に賢いんです。単なるキーワードの一致ではなく、意味的なゆらぎを吸収してくれる。これが「Dataverse 検索の本来の実力」ということになります。
【検証②】日本語環境で「フリーズ」と入れたら……沈黙
さて、日本語環境です。
英語の検証で気分が上がっていたところに、現実を突きつけられました。
テストデータの中に「フリーズする」という問い合わせ内容が入っているものがあります。まず「フリズ」(わざと誤字)で検索しました。
ヒット:0件。
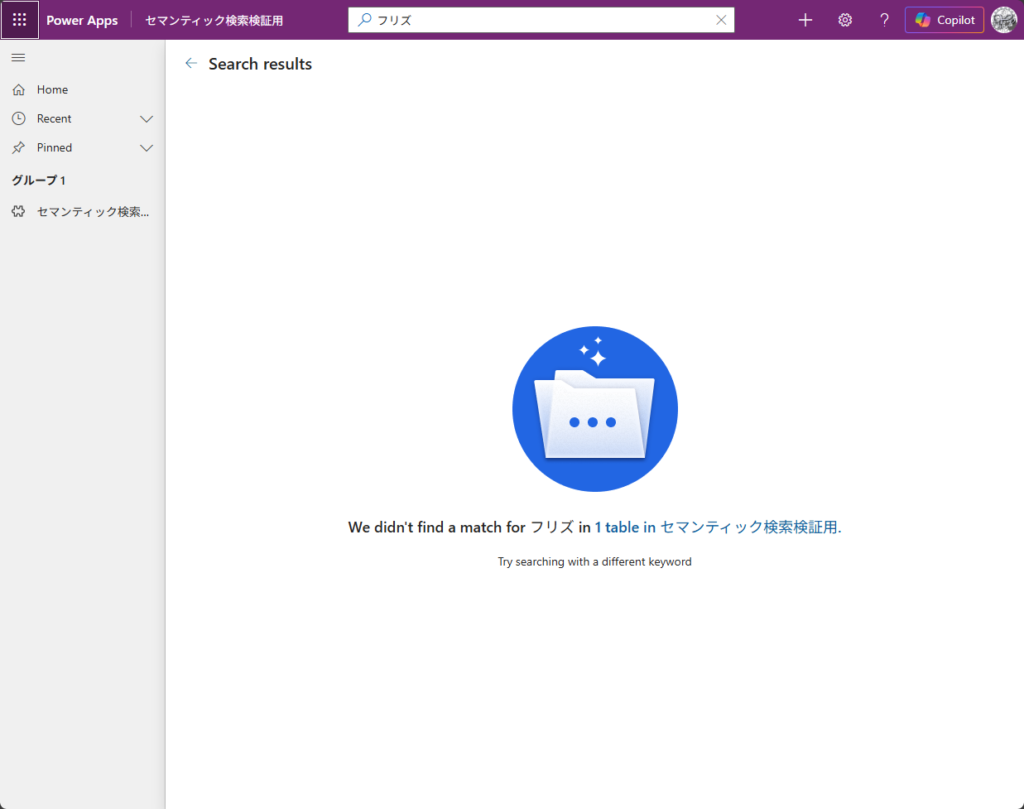
「まあ誤字だからね」と気を取り直して、今度は正しく「フリーズ」と入力しました。
ヒット:0件。
(……え?正解を入れても出てこないの?)
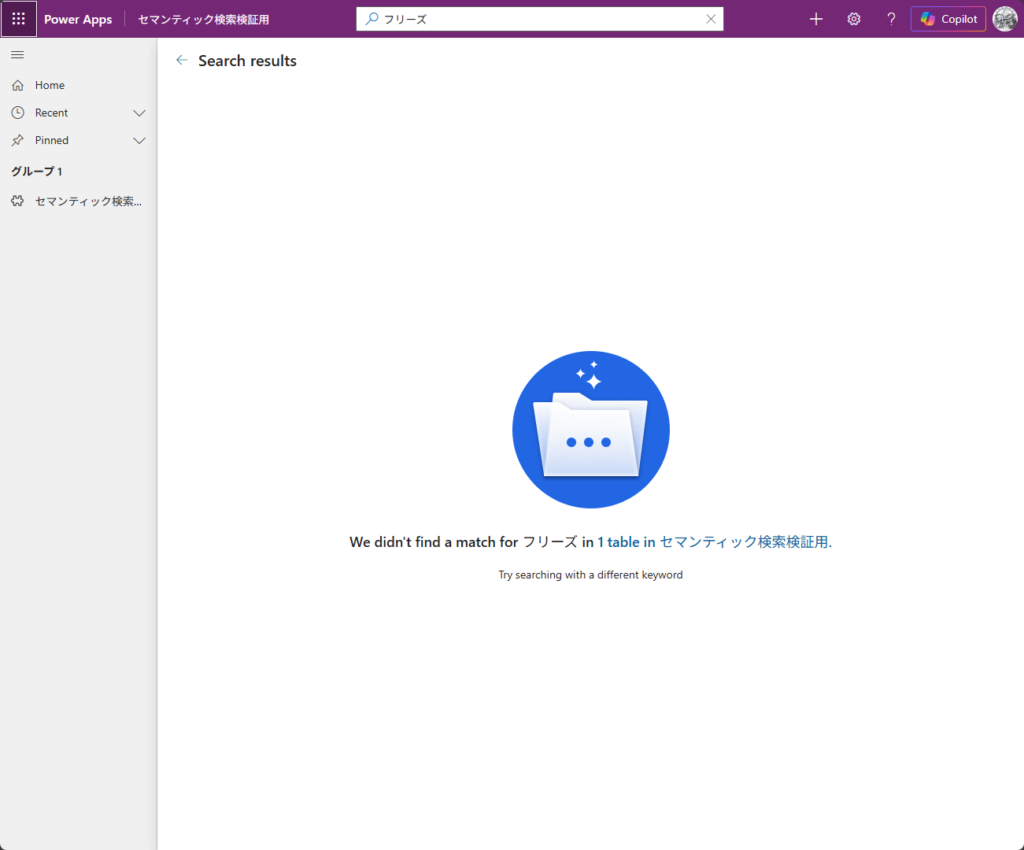
英語環境が誤字を補正してヒットを返してくれたのとは、まったく対照的な結果でした。
なぜ日本語はダメなのか?「MacBook」が答えを教えてくれた
「フリーズ」がヒットしないなら、試しに別の言葉を入れてみようと思いました。
データの中には「MacBookが起動しない」という内容のレコードがあります。そこで「MacBook」で検索してみると——
ヒットしました!
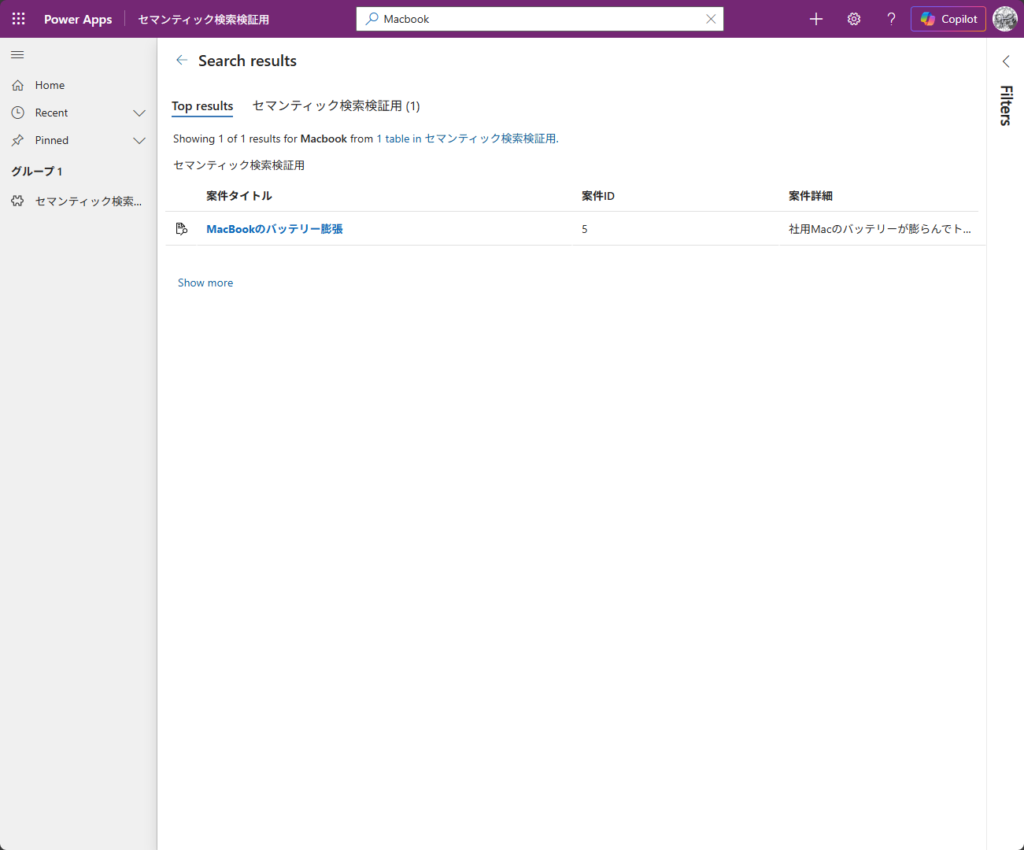
この結果から見えてくることがあります。
Dataverse検索は、日本語環境でもインデックス自体は作成されています。英単語(MacBookやWi-Fiなど)はちゃんとヒットするんです。
では何が違うのか。実は日本語環境にも、日本語専用の「アナライザー」が自動で適用されています。ただ、このアナライザーには英語環境のようなタイポ補正やあいまい検索の機能がないんです。
英語なら「erorr → error」と補正してくれる仕組みが、日本語では動かない。だから「フリーズ」と正しく入力しても、表記のわずかなゆらぎを吸収しきれずヒットしない——というケースが起きてしまいます。
💡 ポイント:日本語アナライザーはあるのに、なぜ弱いのか?
実はDataverse検索は、組織の言語設定に合わせて日本語用のアナライザーを自動的に適用しています。つまり「アナライザーが存在しない」わけではありません。
問題は、このアナライザーがタイポの補正やあいまい検索(ファジー検索)に対応していない点です。
英語環境では「erorr→error」のような補正が動きますが、日本語環境ではそのインテリジェントな機能が機能せず、結果としてカタカナの表記ゆれなどには対応できない状態になっています。
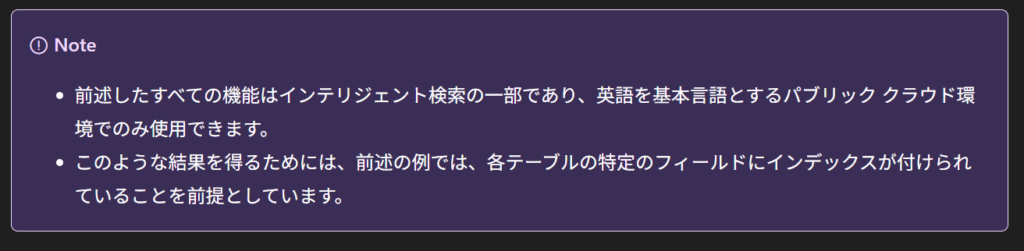
そして、これは「設定次第でどうにかなる」話でもありません。Microsoftの公式ドキュメントには、スペルミス補正・同義語展開・自然言語理解といったインテリジェント検索の機能は、「英語を基本言語とするパブリッククラウド環境でのみ使用できる」と明記されています。日本語環境では、そもそもこれらの機能が提供されていないんです。
残念・・・
【参考】
Dataverse 検索を使用してレコードを検索する – Power Apps | Microsoft Learn
もう一つの「壁」:数値型の列は検索できない
検証中にもう一つ確認できたことがあります。
ID列のような数値型の列を対象に検索しても、日本語・英語どちらの環境でもヒットしません。
これは「設定が悪い」のではなく、Dataverse検索の仕様です。公式ドキュメントにも明記されていますが、検索対象になるのは基本的にテキスト系の列(1行テキスト、複数行テキスト、選択肢など)に限られます。
こちらも上述のLearnに記載があります。

「ID番号で検索したい」という要件がある場合は、別のアプローチを考える必要があります。(ここは要注意ポイントです!)
今回の検証結果まとめ:あなたのせいじゃない、仕様の壁だった
今回の実機検証で確認できたことを整理します。
- 英語環境では「erorr」→「error」のタイポ補正が動作し、インテリジェントな検索が機能する
- 日本語環境では正しいキーワードを入力してもヒットしないケースがある
- 日本語環境でも英単語(MacBook・Wi-Fiなど)はヒットする=インデックスの問題ではなく日本語アナライザーのファジー検索非対応の問題
- 数値型の列は仕様上、検索対象外(両環境共通)
- 設定変更後は「すべてのカスタマイズを公開」が必須
「検索がヒットしない」のは、あなたの設定ミスではありません。
Dataverse検索の日本語対応が、現時点では英語環境と比べて大きく見劣りする——それが実機検証で確認できた「仕様の壁」です。
まとめ
今回やってみて感じたのは、「現状のDataverse 検索に日本語の表記ゆれ吸収を期待するのは難しい」ということです。
よく言われる対策として「キーワード列を自作して、そこに関連語を全部詰め込む」という方法があります。ただ、これは正直かなり泥臭い運用になりますし、メンテナンスが大変です。(キーワードが増えるたびに人力で追加するの?ってなりますよね)
ただこのままだと悔しい。
どうにかして日本語でもDataverse 検索的なセマンティック検索をしたい!ということで次回はCopilot Studioを使った検索を試してみようと思います。検索の前段にAIを挟んで、ユーザーの入力を「Dataverseが引きやすい形」に変換してあげる——というアプローチです。
この検証は次回の記事でしっかりやっていこうと思っています!お楽しみに。
まずは今回の内容を踏まえて、「検索がヒットしない原因が設定なのか仕様なのかを切り分ける」ところから始めてみてください。原因がわかるだけで、だいぶ心が楽になりますよ!
それでは皆さん、良い業務ハックライフを~!


コメント