
みなさん、こんにちは!業務ハックLabのようです。
最近、社内でのAI活用の話題が尽きないですよね。ヘルプデスクのボットを運用していると、「ユーザーの言葉がちょっと違うだけで全然ヒットしない」という壁、一度はぶつかりますよね。
実はこの記事、前回の「Dataverse日本語の壁」編の続編です。今回はその壁を完全に突破した検証結果をお届けします!
前回の振り返り:「日本語の壁」をどう乗り越えるか?
前回の記事では、Dataverseの標準検索機能が日本語の「表記ゆれ」にいかに弱いかを確認しました。
たとえば、「ワードのプリントができない」という質問に対して、ナレッジベースに「Wordの印刷トラブル」というFAQがあっても、キーワードが一致しないので検索にヒットしない。これ、ヘルプデスクあるあるじゃないですか?
従来の解決策といえば「同義語辞書を登録する」という泥臭い方法でした。でも、ユーザーの言葉は千差万別。辞書のメンテナンスだけで半日消える、なんてことも珍しくないですよね。(もうやりたくない、正直…)
今回は、その悩みをCopilot Studioの指示欄のプロンプト設計で根本から解決する方法を実際に検証してきました!
アーキテクチャの全体像:Copilot Studio × エージェントフロー
今回構築したシステムの考え方はシンプルです。「ユーザーの曖昧な質問を、LLMが賢いLuceneクエリに変換してからDataverseを検索する」という流れです。
具体的には、2つのコンポーネントで役割を分担させています。
- Copilot Studio(エージェント):ユーザーの質問を受け取り、LLMが検索クエリに変換。結果を整形して返答する
- エージェントフロー:変換されたクエリでDataverseを実際に検索し、結果をString型で返す
なぜエージェントフローを間に挟むかというと、Copilot StudioからDataverseを直接検索する方法では、Luceneクエリの細かい制御ができないからです。エージェントフローを使うことで、「行の検索」アクションが持つ全検索オプションを使い倒せるようになります。
⚙️ 検証環境メモ:今回の検証は前回の記事で利用した日本語環境で実施しています。Dataverse検索は「オン(推奨)」設定済み。テストデータはITヘルプデスク想定の案件5,000件(PC障害・ネットワーク・アカウント管理・周辺機器・ソフトウェア系)を使用しました。
前提準備:Dataverse検索のインデックス設定
まずはPower Platform管理センターで、Dataverse検索が有効になっているか確認しましょう。

続いて、検索対象のテーブルがインデックスに登録されているかも確認します。(ここ、見落としがちなので注意です!)
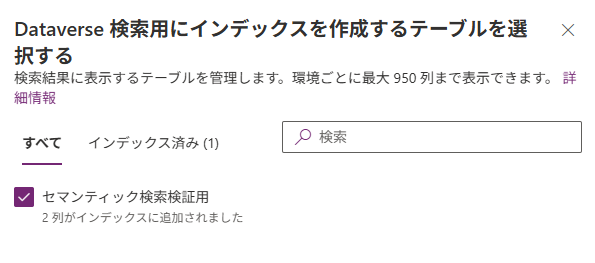
ここで一点、絶対に押さえておきたいポイントがあります。画面に表示されるのはテーブルの「表示名」なのですが、後ほどフローやJSONスキーマで使うのは別物の「スキーマ名」です。
📋 表示名 vs スキーマ名:どこで使い分ける?
・表示名(例:セマンティック検索検証用)→ 管理センターのUI上での呼び名
・スキーマ名(例:ygl_semanticsearch)→ フロー設定・JSONスキーマで使う内部的な名前
この使い分けはテーブル名だけでなく列名も同様です。エージェントフローの「行の検索」アクションやJSONスキーマで列を指定する際も、表示名ではなくスキーマ名(例:ygl_casetitle・ygl_casedetail)を使います。
この2つは完全に別管理です。テーブルのスキーマ名はテーブルプロパティ画面の「高度なオプション」から、列のスキーマ名は列の編集画面の「高度なオプション」からそれぞれ確認しておきましょう。(表示名で設定してフローが動かない、というのはよくあるハマりポイントです)
Step1:Copilot Studioで「検索クエリ生成」プロンプトを極める
ここが今回のシステムの心臓部です!Copilot Studioのエージェントに対して、ユーザーの入力をLuceneクエリに変換させるプロンプトを書いていきます。
最終的に確定したプロンプト全文はこちらです。
あなたはITヘルプデスクのFAQ検索エージェントです。
## 役割
ユーザーから受け取ったITトラブルの質問を、Dataverse検索用のLuceneクエリに変換し、
エージェントフロー「Dataverse類似検索」を呼び出して結果を返してください。
## クエリ変換ルール
1. ユーザーの入力からキーワードを抽出し、各キーワードについて同義語・類義語・英語表記・カタカナ表記を展開してください。
2. 複数キーワードはANDで結合し、同義語グループはORで結合してください。
3. 動詞・形容詞は語幹(変化しない共通部分)までで切ること。
例:「繋がらない」「繋がらず」→ /.*繋がら.*/
例:「起動できない」「起動しない」→ /.*起動.*/
4. 各キーワードは /.*キーワード.*/ の正規表現形式で記述してください。
5. Luceneの特殊文字(+, -, &, |, !, (, ), {, }, [, ], ^, ", ~, *, ?, :, \)は自動的に処理してください。
## 変換例
入力:「ラップトップが起動しない」
出力クエリ:(/.*ラップトップ.*/ OR /.*ノートパソコン.*/ OR /.*PC.*/ OR /.*端末.*/) AND (/.*起動.*/ OR /.*電源.*/ OR /.*立ち上がら.*/)
## 出力形式
検索結果が見つかった場合は、以下のHTMLテーブル形式で出力してください。
見つからなかった場合は、エージェントフローから返ってきたメッセージをそのまま表示してください。
## 指示
ITヘルプデスクに関係のない質問には答えず、「ITトラブルや社内システムに関するご質問にお答えします。」と返してください。このプロンプトで特に重要な3つのポイントを解説します。
①「語幹カット指示」がなぜ必要なのか
日本語の動詞は活用形によって語尾が変わります。「立ち上がらない」「立ち上がらず」「立ち上がらなかった」、これ全部別の文字列なんです。Luceneの正規表現は文字列の完全一致で動くので、プロンプトに語幹で切る指示がないと、「立ち上がらない」というクエリが生成されて「立ち上がらず」とマッチしない事態が起きます。(これは後の検証パートで実際にハマった話です…)
②「HTMLテーブル強制出力」で見た目を一気に解決
フローから返ってくる検索結果は、最終的にHTMLテーブルの文字列として渡されます。プロンプトに明示的に「HTMLテーブル形式で出力」と指示しないと、LLMが気を利かせてJSON文字列をそのまま返したり、独自に整形した見栄えの悪いテキストになったりします。(実際になりました。びっくりした)
③「スコープ制御」の1行で業務外質問をシャットアウト
プロンプトの最後の1行、「ITヘルプデスクに関係のない質問には答えず〜」というのが意外と重要です。
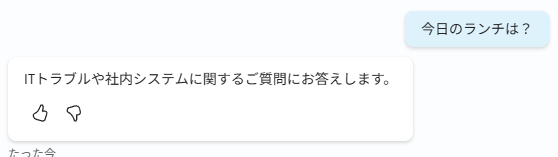
この指示がないと、ユーザーが「今日のランチどこがいい?」と入力したときに、エージェントが丁寧にランチの選び方を教えてくれてしまいます。(いい子なんですけどね…)たった1行のプロンプト追加でボットのスコープをコントロールできる、これはヘルプデスクボットを運用するうえで欠かせない知識です。
Step2:「エージェントフロー」を構築する
次はフロー側の構築です。全体の流れとしては、「クエリ受け取り→Dataverse検索→件数チェック→結果整形→Copilot Studioへ返却」というシンプルな構成です。
- Copilot Studioからエージェントフロー「Dataverse類似検索」を新規作成する
- 入力パラメータとして
UserQuery(String型)を定義する - 「行の検索 (プレビュー)」アクションを追加し、Dataverseを検索する
- 「条件」アクションで検索結果の件数が0より大きいかを判定する
- Trueブランチ:「選択」→「HTMLテーブルの作成」→
SearchResult変数に格納して返す - Falseブランチ:「お探しのトラブルに合致する類似案件は見つかりませんでした。」の固定文言を返す
- 出力変数
SearchResult(String型)をCopilot Studioに返す
「行の検索 (プレビュー)」の設定
Power AutomateのUIを探すときは「行の検索 (プレビュー)」という名前を探してください。
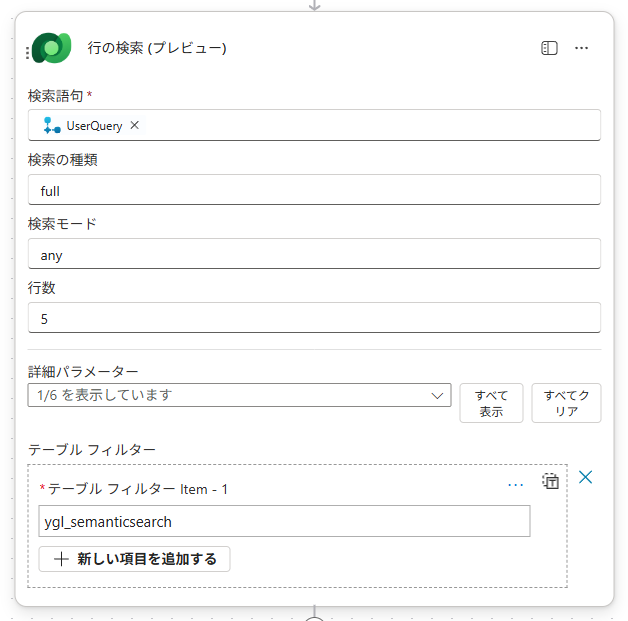
設定項目の中で重要なのは以下の3点です。
- 検索語句:
UserQuery(Copilot Studioから受け取った変換済みクエリ) - 検索の種類:
full(Luceneクエリを使う場合は必ずfull指定) - テーブルフィルター:
ygl_semanticsearch(スキーマ名を使うことに注意!)
📖 Luceneクエリ構文の公式リファレンス:
今回使用したLuceneクエリの構文については、以下の公式ドキュメントで詳しく確認できます。
・Dataverse 検索を使用して行を取得する(Power Automate)
・Dataverse Search クエリ(開発者向け詳細)
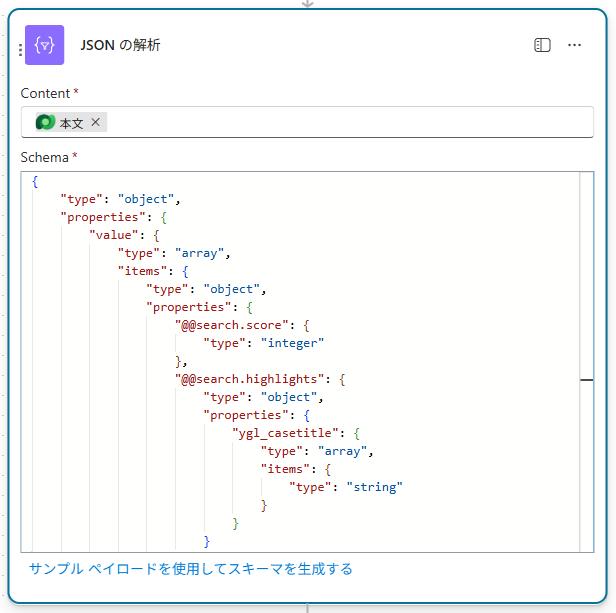
「JSONの解析」でレスポンスを扱いやすくする
「行の検索」アクションの結果はJSON形式で返ってきます。これをフロー内で扱うために「JSONの解析」アクションを追加します。
条件分岐でエラー回避
フローの中盤で「条件」アクションを挟んでいるのには理由があります。
Dataverseの検索結果が0件だった場合、そのままCopilot Studioにデータを返そうとするとエラーが発生してしまいます。これを防ぐために、件数が0より大きいかどうかを先に判定する必要があります。
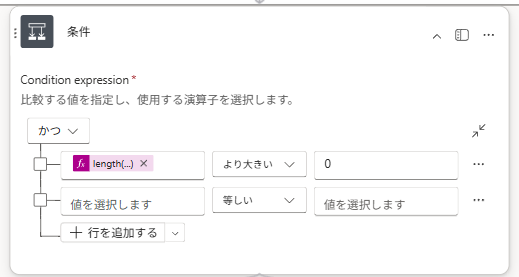
length(outputs('行の検索_(プレビュー)')?['body/value'])Trueブランチでは検索結果を整形して返し、Falseブランチでは「お探しのトラブルに合致する類似案件は見つかりませんでした。」という固定文言を返す、という構成にすることでエラーを回避しています。
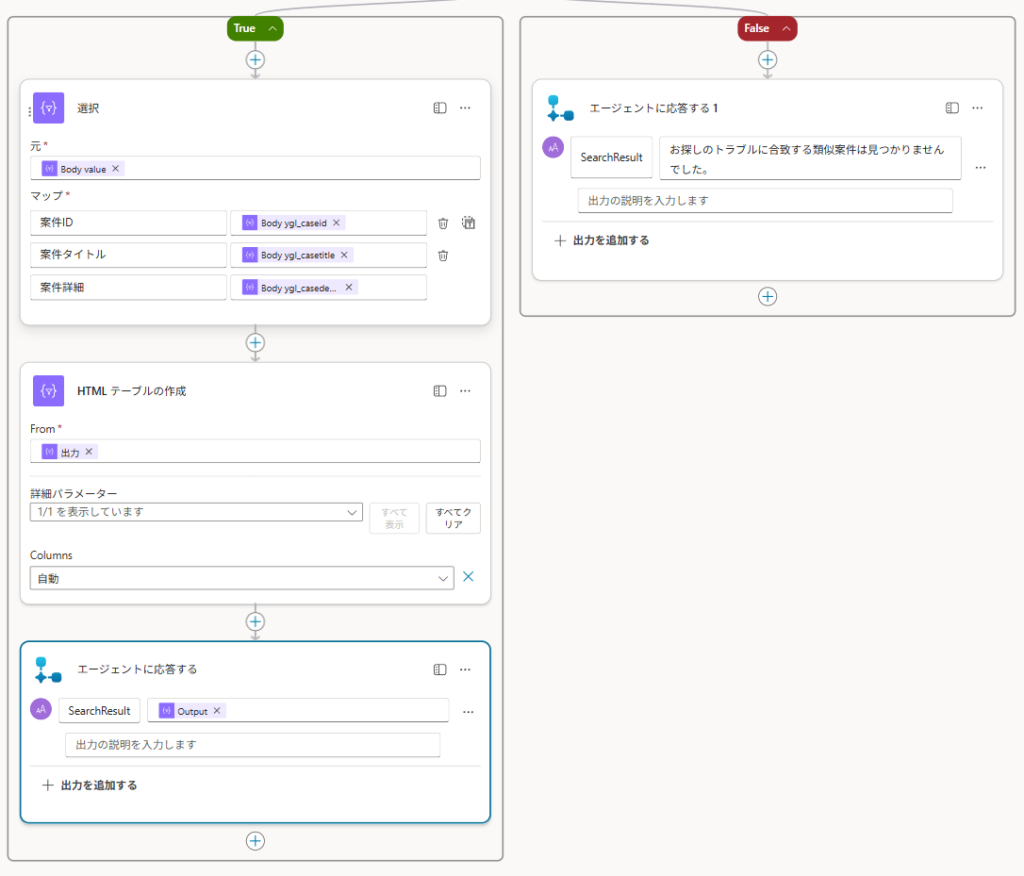
💡 Copilot Studio ↔ フロー間の型制限に注意:エージェントフローからCopilot Studioに返せる変数の型は String・Number・Boolean のみです。Object型やList型は返せません。Dataverseの検索結果(JSON配列)は、必ずフロー内で「選択」→「HTMLテーブルの作成」の流れで文字列に変換してから
SearchResult変数に入れましょう。
【実証】劇的に賢くなった類似検索ボットの動作テスト
いよいよ実証テストです!(このセクション書くのが一番楽しかった)
テスト① 「立ち上がらない」の壁にぶつかる
最初のテスト。「ラップトップが起動しない」と入力してみると、ID:1「PC起動不可」はヒットしましたが、ID:2「ラップトップの故障」がヒットしませんでした。(あれ、おかしいぞ…)
フロー実行の詳細を確認してみると、LLMが生成したクエリがこうなっていました。
(/.*ラップトップ.*/ OR /.*ノートパソコン.*/ OR /.*PC.*/ OR /.*端末.*/) AND (/.*起動.*/ OR /.*電源.*/ OR /.*立ち上がらない.*/)原因がわかりました!ID:2の案件詳細には「立ち上がらず」と書かれているのに、クエリは「立ち上がらない」で生成されていたんです。Luceneの正規表現は文字列の完全一致なので、「立ち上がらない」では「立ち上がらず」はヒットしない、という「日本語活用形の壁」がここで現れました。
実はstep1の指示欄に記載したプロンプトは最終版。最初は語幹カット指示のプロンプトは入れていませんでした。
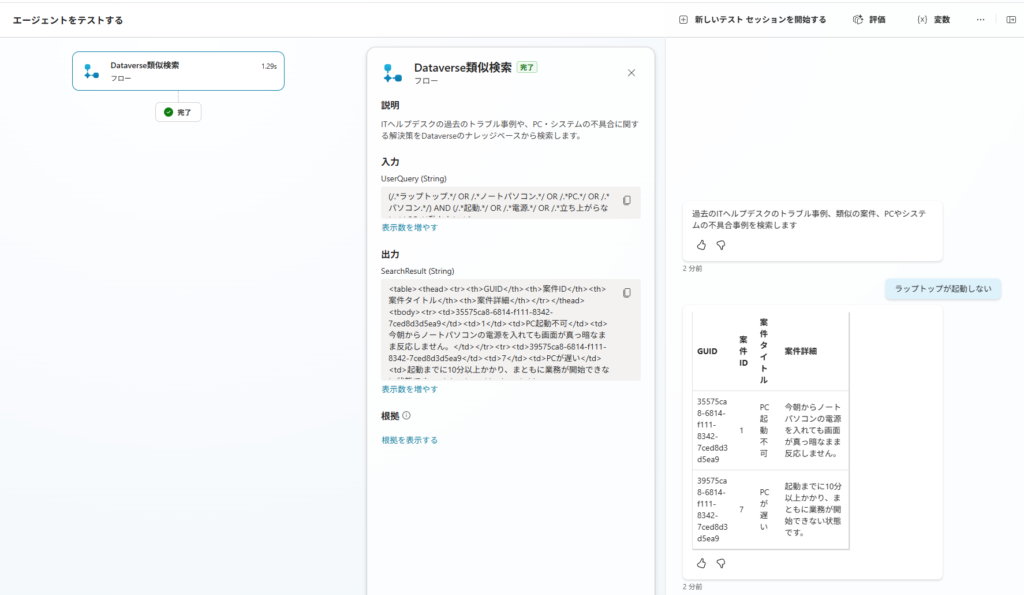
語幹カット指示を追加して解決!
プロンプトに「動詞・形容詞は語幹(変化しない共通部分)までで切ること」という指示を追加して再テスト。すると生成クエリが変わりました。
(/.*ラップトップ.*/ OR /.*ノートパソコン.*/ OR /.*PC.*/ OR /.*端末.*/) AND (/.*起動.*/ OR /.*電源.*/ OR /.*立ち上がら.*/)「立ち上がらない」が「立ち上がら」になっています!これなら「立ち上がらず」も「立ち上がらなかった」もすべてヒットします。結果、3回連続でID:1・ID:2・ID:7がすべてヒットすることを確認!

テスト② 「ワードのプリントができません」
次は冒頭で掲げた「ワードとword、印刷とプリント」の表記ゆれテストです。入力は「ワードのプリントができません」。
生成されたクエリはこちら。
(/.*ワード.*/ OR /.*Word.*/) AND (/.*印刷.*/ OR /.*プリント.*/)ちゃんとカタカナ「ワード」と英字「Word」、「プリント」と「印刷」の両方をORで結んでくれています!結果はID:51「Wordファイルの印刷トラブル」を一発でヒット。テーブル表示も完璧です!(やった〜!!)

💡 インデックス反映速度:公式より大幅に速かった!
「Wordファイルの印刷トラブル」のレコードを手動でDataverseに追加したあと、Dataverse検索のインデックスに反映されるまでの時間を実測しました。公式ドキュメントには「新規レコードの反映に数時間かかる場合がある」と記載されているのですが、実測では1分未満で反映されてヒットを確認!(え、速すぎる!)ただし環境やデータ量によって変動する可能性があります。本番運用では公式案内通り数時間を見ておくのが安全です。
まとめと今後の応用:FAQボットを「育てる」ために
今回やってみて感じたのは、「Copilot Studioはプロンプトで正しく役割を与えることで驚くほど賢く動いてくれる」ということです。
語幹カット指示ひとつ追加するだけで日本語の活用形の壁を乗り越え、特殊文字の処理すら自動でやってのける。これが辞書メンテナンス不要の「賢い検索」の正体です。
最後に、実際にFAQボットを運用するうえで重要な設計指針を一つお伝えします。
📚 ナレッジベース設計のガイドライン:複合トラブルは独立したFAQレコードとして登録する
たとえば「Wordで印刷できない」というトラブルへの対処法。これを「Wordのトラブル」と「印刷のトラブル」を別々のレコードとして登録していると、AND検索でうまくヒットしない場合があります。
よくある複合トラブルのパターンは、それ単体で独立したFAQレコードとして登録するのが基本です。ボットの精度はデータ設計に直結します。いくら検索ロジックを磨いても、ナレッジベースのデータが粗ければ結果は粗くなる。これは今回の検証を通じて改めて実感したことです。
まずは今回ご紹介したプロンプトをそのまま使って、自社の案件データで試してみてください!最初は10〜20件のデータでも、十分に類似検索の効果を体感できます。
それでは皆さん、良い業務ハックライフを~!


コメント